
Informação dispersa e o custo invisível
“Como eu peço um banco de dados novo?”, “E um repositório?”, “Não sei como pedir reembolso, me ajuda?”.
Quantas mensagens dessas circulam na sua empresa todo dia? E cada vez que alguém gasta tempo para responder, quanto custa? E quando seu projeto fica parado esperando uma resposta dessas ou você achar a informação perdida em alguma página no Sharepoint ou Confluence?
E se, usando apenas o que você já tem hoje na sua infraestrutura, fosse possível reduzir centenas de e-mails e mensagens por mês e economizar dezenas de horas de pessoas-chave?
É exatamente isso que este post propõe: mostrar, passo a passo, como montar uma base de conhecimento com RAG usando AWS Bedrock e expor tudo como um chatbot interno que realmente responde às dúvidas do dia a dia.
Custo da solução e retorno
Antes de entrar nos detalhes técnicos, vale ver quanto custa operar essa solução em produção.
| Consultas/mês | Modelo | API Gateway | Lambda | Custo total estimado (USD) |
|---|---|---|---|---|
| 1.000 | $0.875 | ~$0.0035 | ~$0.0002 | $0.88 / mês |
| 10.000 | $8.75 | ~$0.035 | ~$0.002 | $8.79 / mês |
| 1.000.000 | $875.0 | ~$3.50 | ~$0.20 | $878.70 / mês |
Com esse custo, qualquer redução mínima de tarefas repetitivas já torna a solução altamente vantajosa.
RAG - Retrieval Augmented Generation
Você muito provavelmente já sabe do que se trata, mas para quem ainda não é familiarizado com o termo, RAG é estender a capacidade da IA generativa além de seus dados de treinamento a partir de fontes de dados externas.
Quando você usa o Chat GPT, parte das respostas recentes depende de mecanismos parecidos com RAG — consultas externas, ferramentas e dados atualizados — porque o modelo por si só tem um cutoff de treinamento. Conseuindo assim responder quando perguntamos sobre um fato recente, ou o valor atual de uma ação.
Pensando na nossa ferramenta, e em outras que você irá criar no futuro, o que muda com RAG? Colocar toda a informação que a IA usará para trabalhar no prompt consumiria muitos tokens e esgotaria rapidamente o contexto, e mesmo se nos mantermos dentro da janela, quanto mais próximos ao limite, maior a chance de erros ou alucinações.
É este o problema que RAG resolve. E é assim que resolveremos o problema de disponibilidade de informações da nossa empresa.
A solução
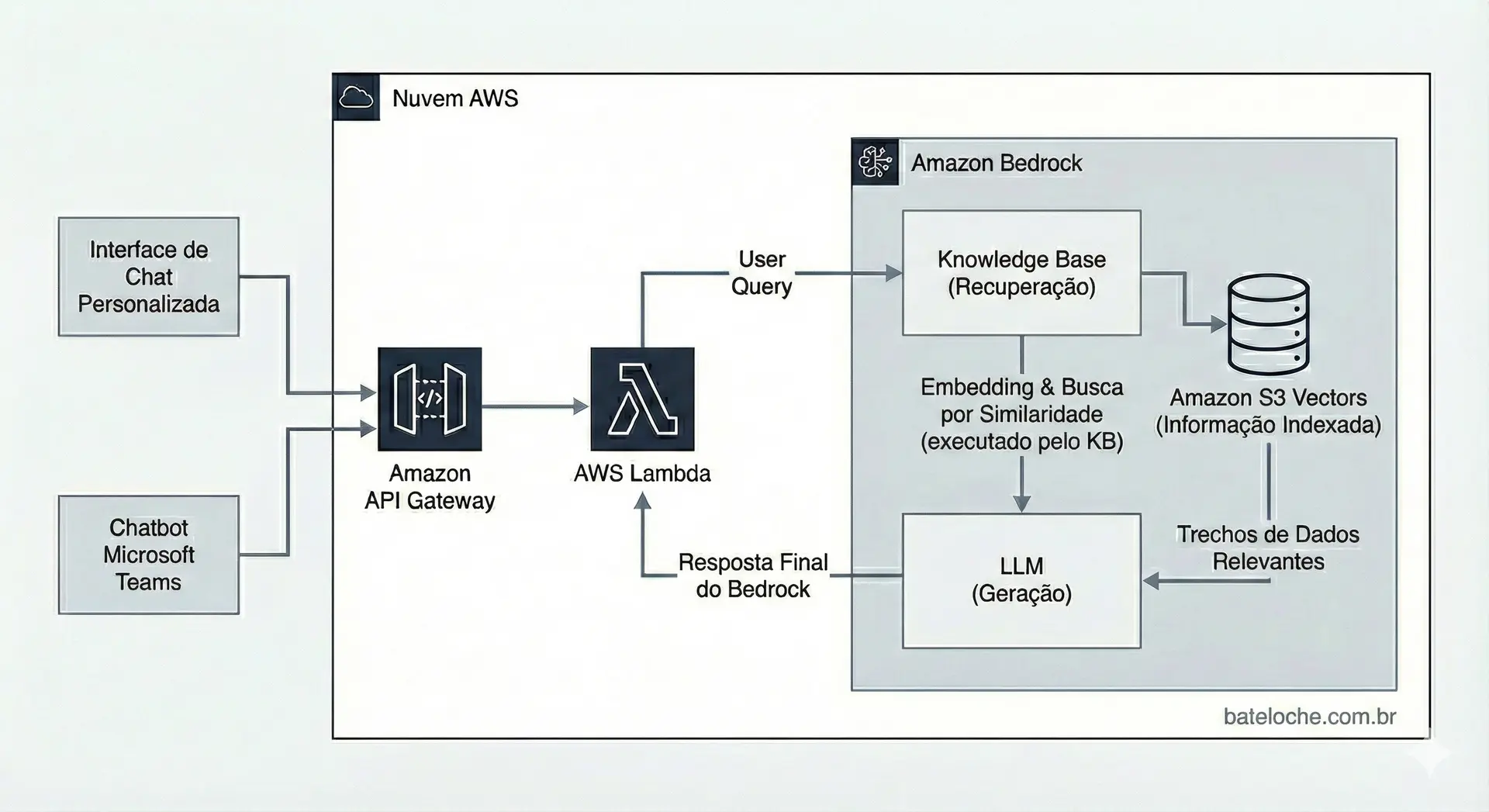
Nós teremos uma interface de chat, e um chatbot do Microsoft Teams consumindo um endpoint do AWS API Gateway para responder às perguntas dos nossos funcionários.
A chamada ao endpoint, acionará uma função Lambda que invova um modelo no Bedrock e a base de conhecimento.
Como funciona a base de conhecimento? Ao fazermos a chamada ao Bedrock, a consulta do usuário é transformada em embeddings que são usados para uma consulta por similaridade na vector store que indexa nossas informações. Os trechos de dados mais relevantes são retornados e adicionados ao prompt para que a LLM possa dar uma resposta mais precisa ao usuário.
Criando o ambiente e a aplicação
Todo o código utilizado nesta demonstação e os arquivos de exemplo estão disponíveis no GitHub.
[!NOTE] Nota Por se tratar de um assunto que atrai interesse de muitas pessoas de fora da área técnica e para ser mais amigável com quem não tem tanta familiaridade com o ambiente, vou usar o console web para a criação do ambiente. Mas tudo que será feito aqui, pode ser criado pelo CloudFormation.
Preparação
Antes de tudo, precisamos subir os arquivos que serão indexados na nossa base de conhecimento. Para a demo, vou usar o S3. No repositório do projeto tem uma série de documentos sintéticos que você pode usar para acompanhar e ter uma boa gama de perguntas possíveis para teste. Você encontra eles diretamente aqui.
[!TIP] Dica Além do S3, as bases de conhecimento do Bedrock fornecem conectores prontos para Sharepoint, Confluence e Salesforce. Além da possibilidade de usar URLs ou seu próprio Vector Database. A primeira ideia para o post era utilizar o Sharepoint por ser o mais usado em ambiente corporativo, mas o acesso a tenants de teste é um tanto restrito pela Microsoft.
Para criar e popular o bucket:
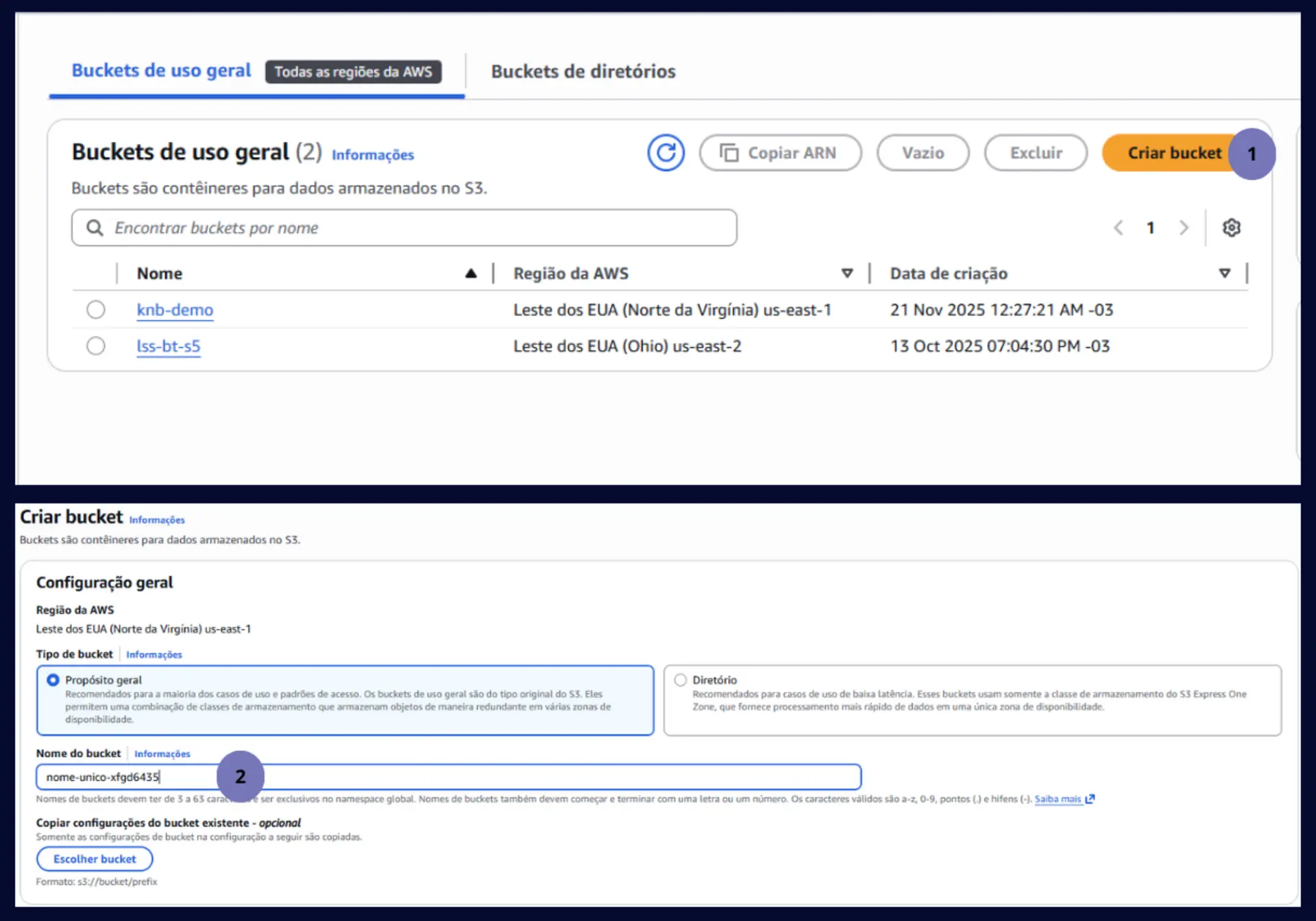
- Criando o Bucket
No console da AWS, busque por S3, acesse a página do serviço e clique em “Criar Bucket”
Defina o nome do bucket que deve ser único e mantenha o restante das configurações padrão.
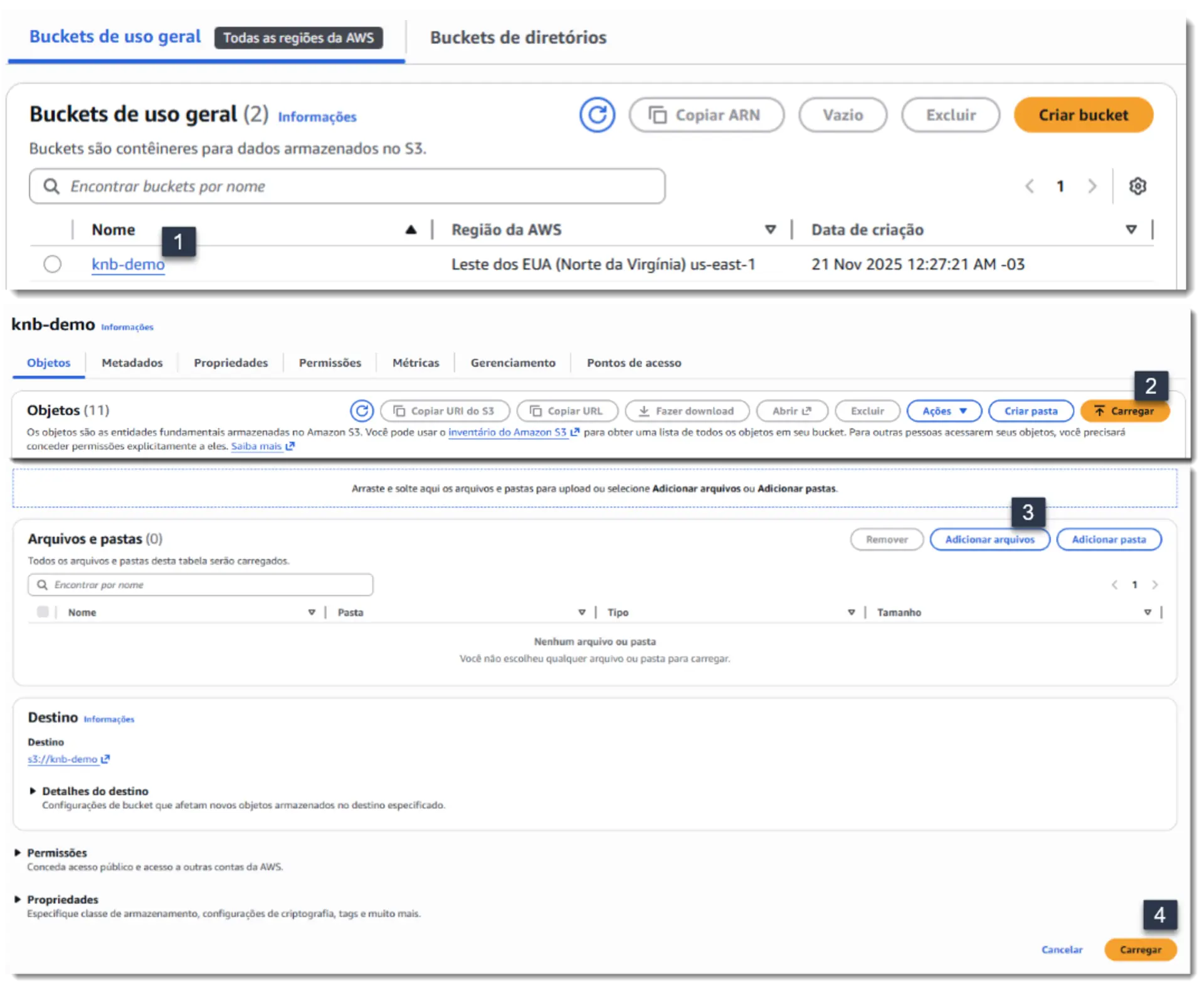
- Fazendo o Upload dos Documentos
Após a criação, precisamos popular o bucket.- Clique no nome do bucket
- Na próxima tela, “Carregar”
- Agora, “Adicionar arquivos”
- Selecione no diálogo, e por fim, “Carregar” no final da página
Montando a Base de Conhecimento
[!IMPORTANT] Aviso Não é possível criar um Knowledge Base a partir do root user da conta AWS, para este passo, pelo menos, você precisará de um usuário do IAM.
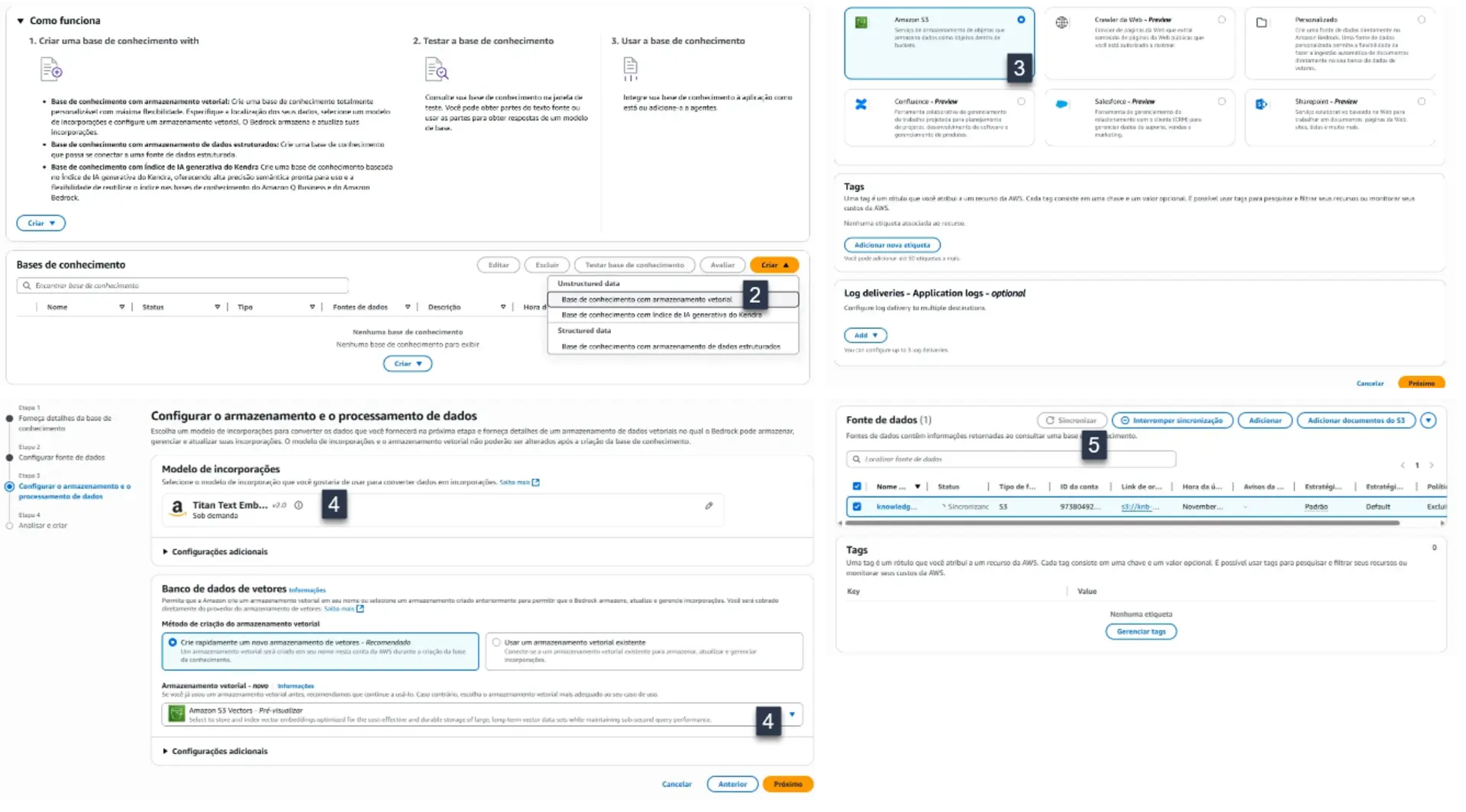
- Criando o KnowledgeBase
- Busque “Bedrock” e acesse “Bases de Conhecimento”
- Clique em “Criar” e em “Base de conhecimento com armazenamento vetorial”
- Selecione S3 como a fonte dos dados
- Escolha o modelo dos embedding e armazenamento
- Usei “Titan Text” e “Amazon S3 Vectors” mas voce pode experimentar e avaliar as diferenças
- Finalize selecionando a base de conhecimento e clique em “Sincronizar”
Terminada a sincronização, estamos prontos para usar a base de conhecimento. Nesta mesma tela já é possível testá-la.
Criando a Lambda para consumo
Agora vamos a criação da lambda, o modo mais simples e utilizado aqui é pela extensão do Visual Studio. A partir dela temos acesso a templates de projetos e deploy diretamente da IDE.
O código é simples, temos apenas a classe KnowledgeBaseService fazendo a chamada ao modelo e a Function que apenas cuida de chamar o serviço e devolver a resposta no formato correto.
O projeto completo está no nosso repositório, mas há dois trechos de código que são importantes para compreensão da solução.
private const string promptTemplate = """
Você é um expert nas políticas internas de nossa empresa, com a missão de tirar dúvidas dos nossos funcionários quanto aos nossos procedimentos.
Considere apenas os dados fornecidos enquanto responde às perguntas.
Se a resposta não estiver contida nos dados fornecidos, diga que não sabe.
Use o contexto abaixo para responder à pergunta no final.
Se o contexto não for informado, responda apenas com 'Não sei'.
Contexto:
{$search_results$}
Question: {$question$}
Responda de maneira clara e objetiva.
""";
Note que o prompt contém dois placeholders, o Bedrock usará a pergunta do usuário para efetuar a busca em nossa base, e o enriquecerá substituindo $question$ pelo texto da pergunta e $search_results$ pelo resultado da consulta. É assim que o modelo recebe as informações para basear a resposta final.
public async Task<string> QueryBase(string question)
{
var request = new RetrieveAndGenerateRequest
{
Input = new RetrieveAndGenerateInput
{
Text = question
},
RetrieveAndGenerateConfiguration = new RetrieveAndGenerateConfiguration
{
Type = RetrieveAndGenerateType.KNOWLEDGE_BASE,
KnowledgeBaseConfiguration = new KnowledgeBaseRetrieveAndGenerateConfiguration
{
ModelArn = modeld,
KnowledgeBaseId = knowledgeBaseId,
RetrievalConfiguration = new KnowledgeBaseRetrievalConfiguration
{
VectorSearchConfiguration = new KnowledgeBaseVectorSearchConfiguration
{
NumberOfResults = maxResults
}
},
GenerationConfiguration = new GenerationConfiguration
{
PromptTemplate = new PromptTemplate
{
TextPromptTemplate = promptTemplate
}
}
}
}
};
var response = await _client.RetrieveAndGenerateAsync(request);
return response.Output.Text;
}
A chamada acima, é muito parecida com InvokeModel que é usado para autocomplete, a diferença, como o nome diz, é que recuperamos algo antes de gerar a resposta. A configuração da origem dos dados e do modelo utilizado para processamento está nos campos ModelArn e KnowledgeBaseId.
O Id da base de conhecimento, pode ser encontrado na página de detalhes do console.
O Arn/Id do modelo, no Catálogo de Modelos do Bedrock. Apenas garanta que a região selecionada é a mesma que será utilizada pela aplicação, pois a seleção de modelos varia por região e nem todos suportam Cross-region Inference.
Agora vamos à publicação, se você estiver utilizando a extensão da AWS para o Visual Studio, basta um botão direito no projeto e selecionar a opção Publish to AWS Lambda. Caso esteja usando outra linguagem ou não tenha a extensão, é possível criar a função e fazer upload do pacote pelo console.
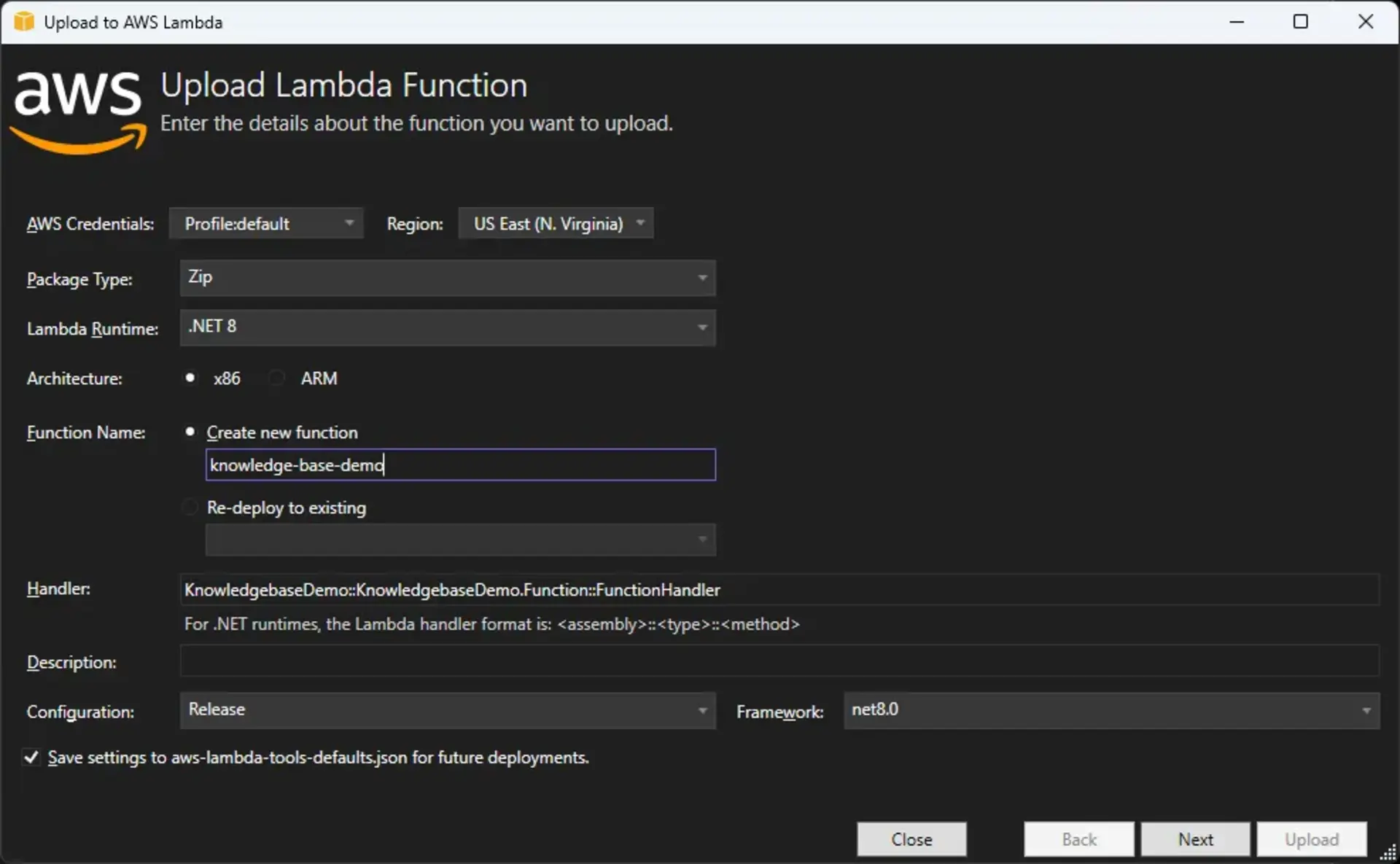
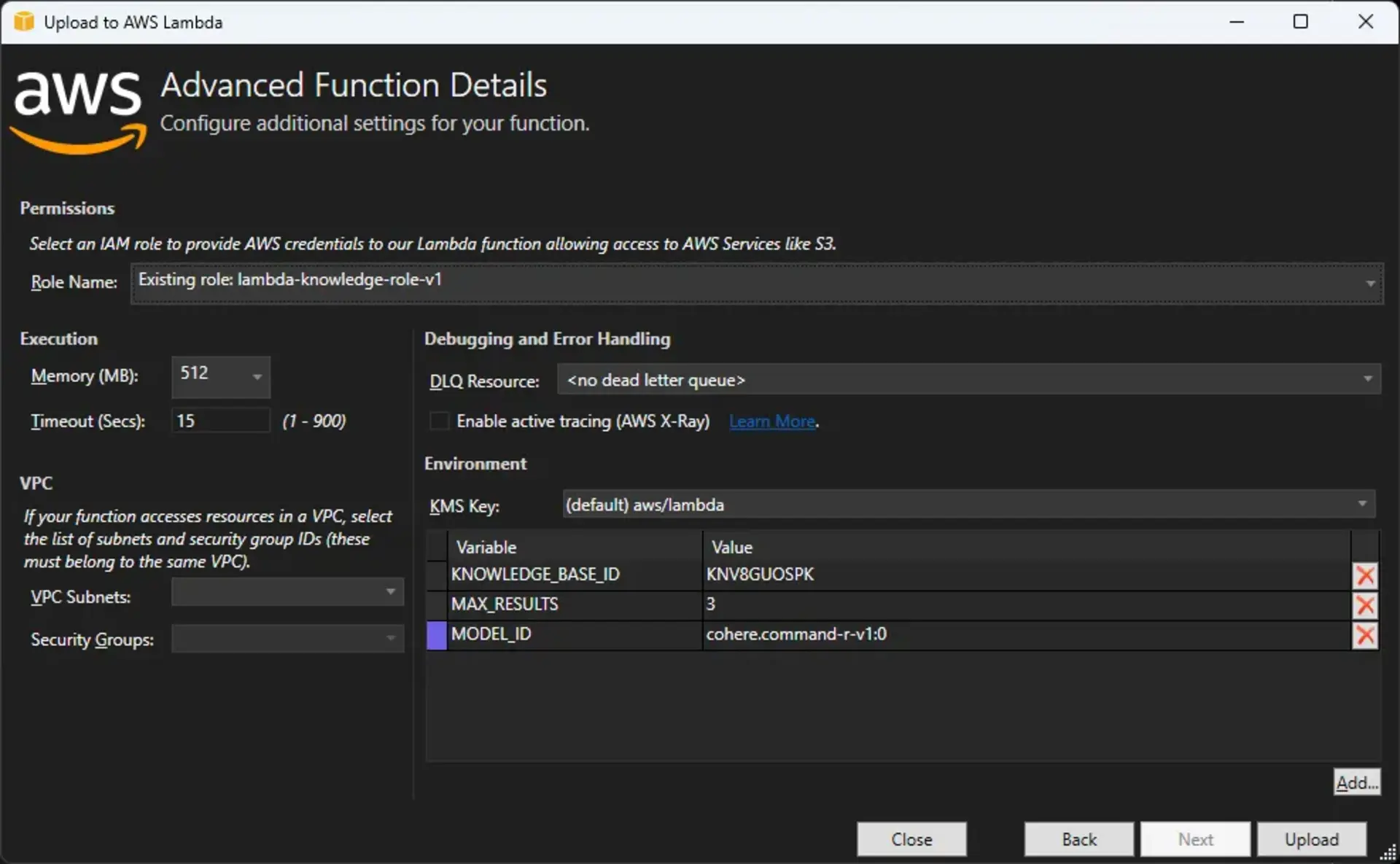
Uma vez publicada, vamos fazer um teste para garantir que configuramos tudo corretamente.
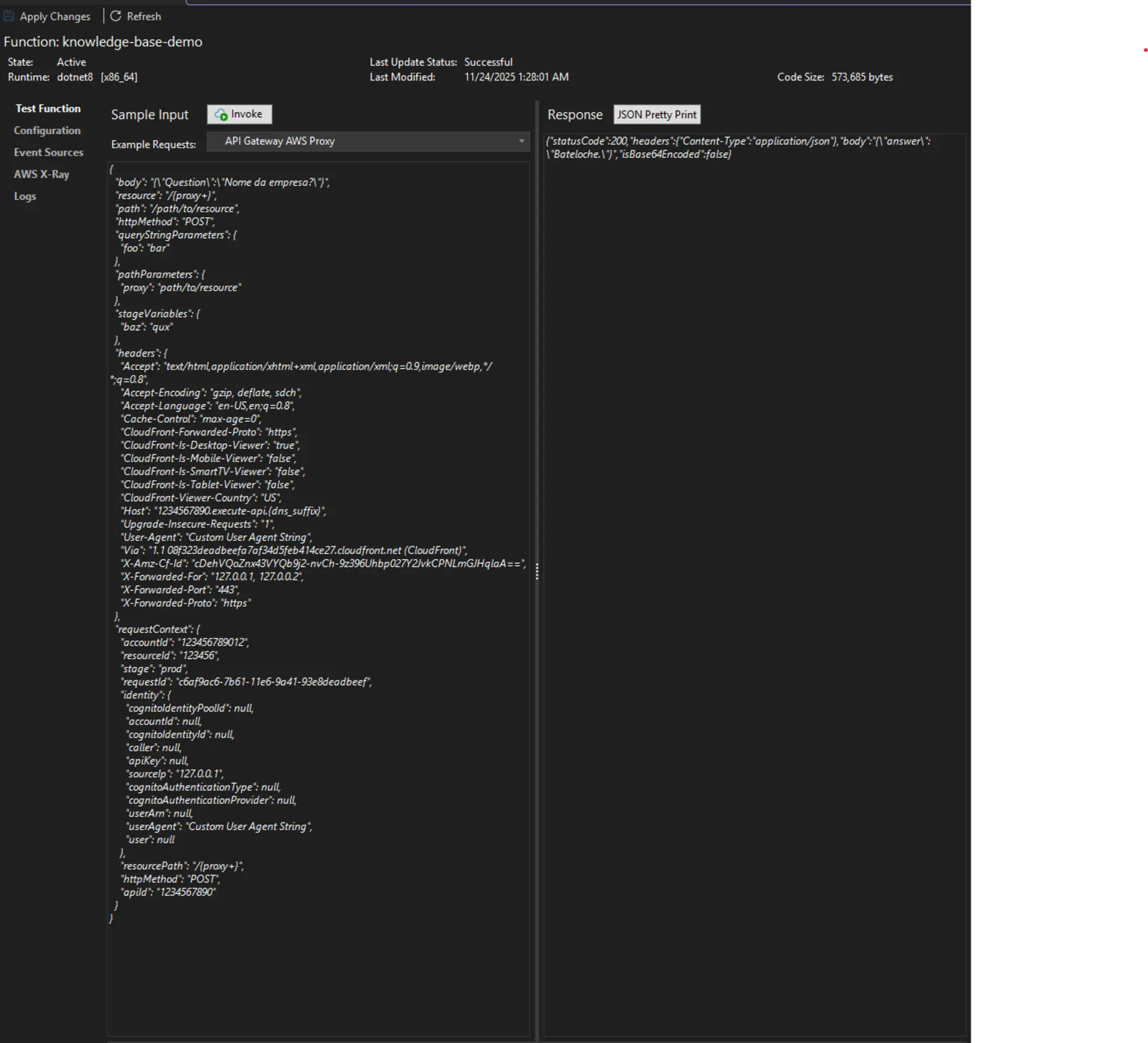
Função testada, o modelo foi capaz de responder de acordo com a documentação fornecida e limitando-se ao conteúdo dela.
Seria possível expor esta função via HTTP e consumir, mas como a ideia é fornecer algo mais realista para aplicação no ambiente corporativo, vamos prosseguir e criar um endpoint no API Gateway.
Endpoint no API Gateway
Na home do API Gateway, escolha a “Criar uma API”, na próxima página, “REST API”. Prencha o nome, garanta que o tipo de endpoint é Regional e selecione Criar API
Agora precisamos criar o recurso utilizado para consulta. Selecione “Criar Recurso” preencha apenas o nome e prossiga.
De volta a tela de recursos, selecione criar método para iniciar a última parte da API.
- Selecione “Função Lamda” e escoolha a função que fez deploy no passo anterior
- Marque o campo “Integração do proxy do Lambda”
- Finalize a criação do método
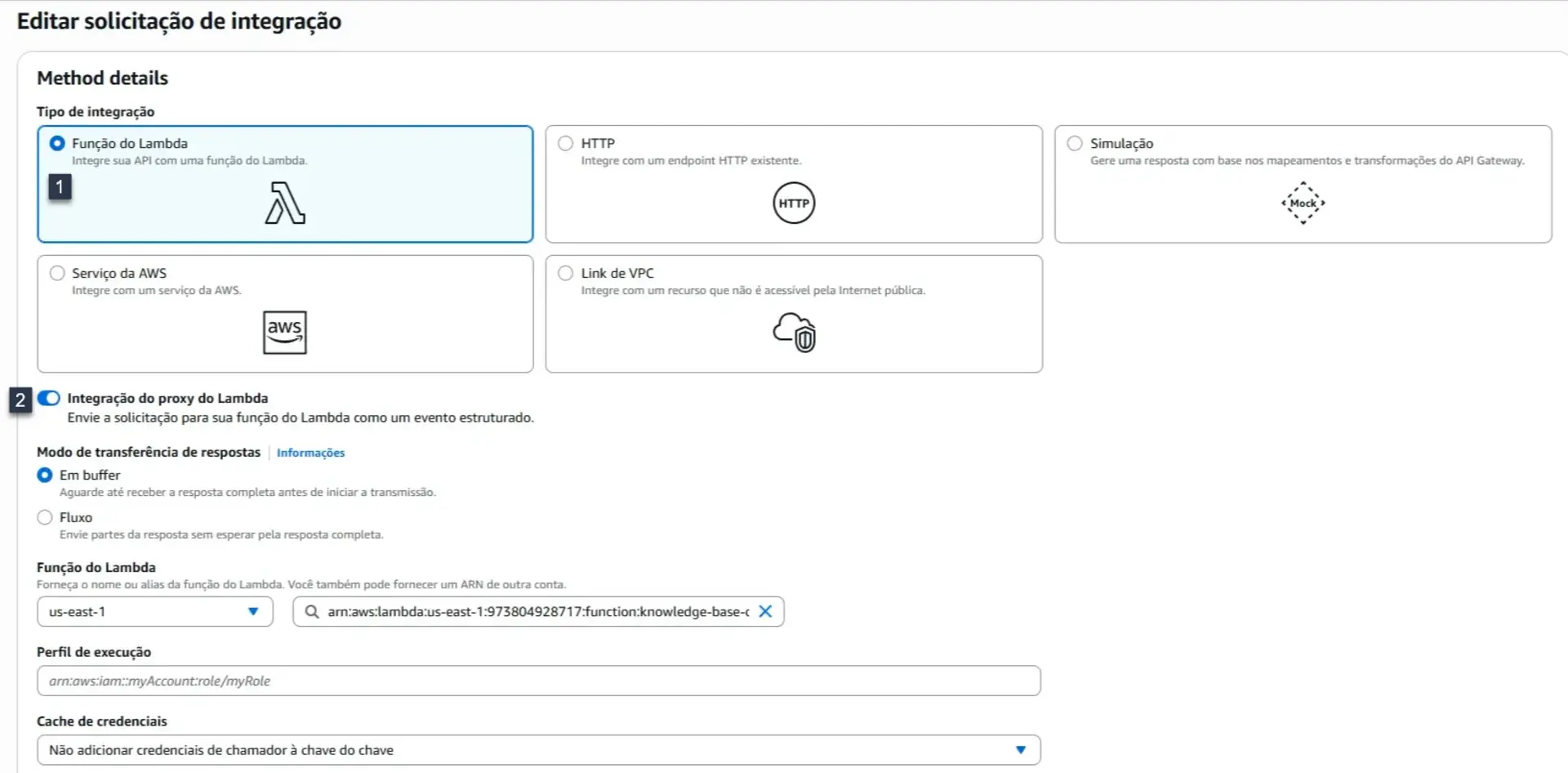
Agora “Implantar API”, selecione novo estágio, dê um nome, e clique em “Implantar”. Após o término do deploy, nossa API está pronta e podemos testar.
Na tela de estágios, temos a URL da nossa API que usaremos para o teste. Vou usar uma interface de chat que está disponível em bateloche.com.br/demos/rag para testar a API.
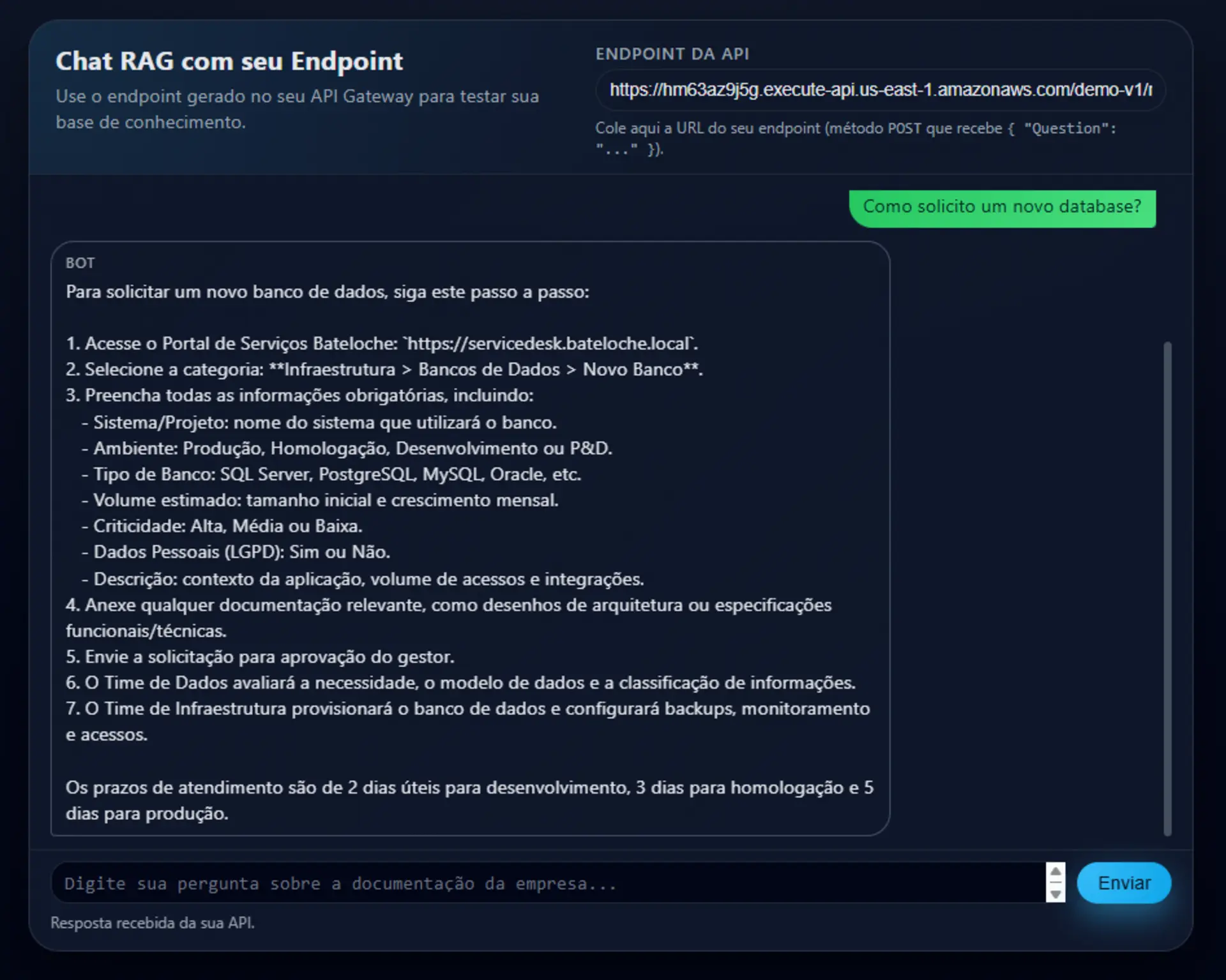
Pronto! A interface continuará disponível no endereço, e caso queria usar para demonstrar a API, troque o endpoint no canto superior direito para o seu endereço.
Apenas lembre-se de habilitar o CORS como no print abaixo.
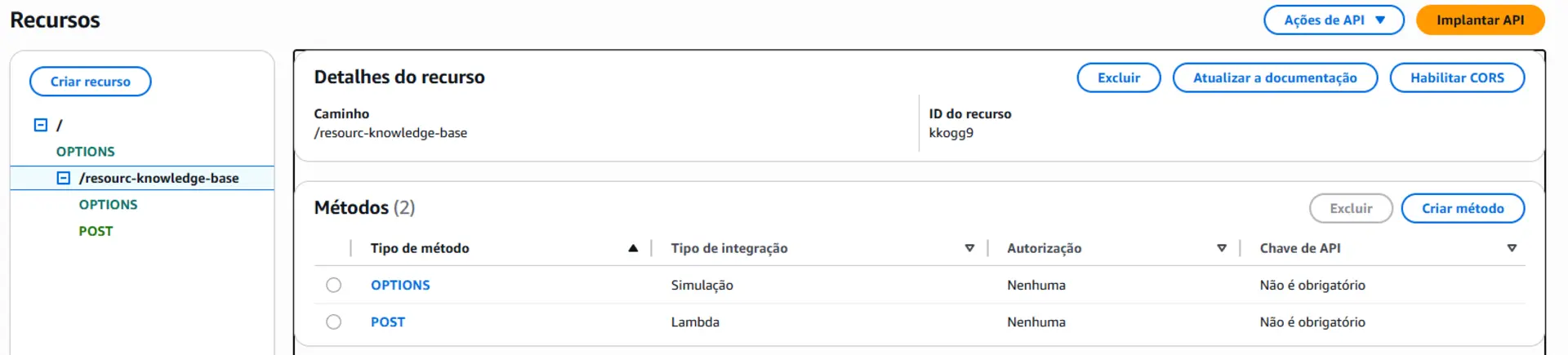
[!IMPORTANT] Caso vá publicar em seu ambiente, lembre-se de configurar a autenticação. A mesma coisa para o Bot do Teams abaixo, consuma a autenticação após configurar a segurança do ambiente.
Bot no teams para uso fácil na sua companhia
Tendo a API publicada, é possível consumir a partir de vários lugares como uma página de intranet, Slack ou onde for mais cômodo. De novo, a política de acesso ao Developer Portal prejudica a demonstração, ala é um tanto restrito para contas pessoais o que impede que eu demonstre aqui tanto o Teams quanto o Sharepoint. O código completo do Bot está no GitHub e você pode baixar e publicar no seu ambiente.
Mas a modificação importante que é feita ao template está aqui, onde consumimos a API de fato:
public virtual async Task<string> GetAnswerAsync(string question)
{
try
{
var url = _endpoint;
var payload = new { Question = question };
var json = JsonSerializer.Serialize(payload);
using var content = new StringContent(json, Encoding.UTF8, "application/json");
using var response = await _httpClient.PostAsync(url, content).ConfigureAwait(false);
response.EnsureSuccessStatusCode();
var responseJson = await response.Content.ReadAsStringAsync().ConfigureAwait(false);
var options = new JsonSerializerOptions { PropertyNameCaseInsensitive = true };
var kbResponse = JsonSerializer.Deserialize<KnowledgeBaseResponse>(responseJson, options);
return kbResponse?.answer ?? string.Empty;
}
catch (Exception)
{
return "Desculpe, não consegui consultar a base de conhecimento no momento. Por favor, tente novamente mais tarde.";
}
}
E na implementação de ActivityHandler para fazer o tratamento da conversa:
public class TeamsBot : ActivityHandler
{
private readonly KnowledgeBaseClient _knowledgeBaseClient;
public TeamsBot(KnowledgeBaseClient knowledgeBaseClient)
{
_knowledgeBaseClient = knowledgeBaseClient;
}
protected override async Task OnMessageActivityAsync(ITurnContext<IMessageActivity> turnContext, CancellationToken cancellationToken)
{
var answer = await _knowledgeBaseClient.GetAnswerAsync(turnContext.Activity.Text);
await turnContext.SendActivityAsync(MessageFactory.Text(answer), cancellationToken);
}
protected override async Task OnMembersAddedAsync(IList<ChannelAccount> membersAdded, ITurnContext<IConversationUpdateActivity> turnContext, CancellationToken cancellationToken)
{
foreach (var member in membersAdded)
{
if (member.Id != turnContext.Activity.Recipient.Id)
{
await turnContext.SendActivityAsync(MessageFactory.Text($"Olá, em que posso ajudar!"), cancellationToken);
}
}
}
}
Conclusão
A IA generativa nos dá não somente maneiras de fazer mais rápido aquilo que, de uma forma ou de outra, teríamos que fazer. Mas possibilita que entreguemos coisas que nunca faríamos. E é aí que estão as oportunidades que mais geram valor.
Neste caso, criamos uma solução, que resolve uma dor real e comum, com pouquíssimo esforço e custo.
E se você tem alguma dúvida sobre o que mostrei aqui, quer adaptar a solução a sua necessidade ou tem sugestões de conteúdos que queria ver neste espaço, entre em contato comigo pelo GitHub, LinkedIn ou um dos links no About deste blog.